*)’,op)iflen(splits)>=2:key,value=splits[:2]options[key]=value# Check strideassert((‘s’inoptionsandlen(options[‘s’])=...
connection, remote)self...
time(),‘thread t is still alive’)should_continue=FalseexceptExceptionase:print(‘error starting thread’)raisee爭議的是透過兩個執行緒...
shape)returny_output#7、誤差反向傳播進行最佳化defbwPropagation(self,W_input,hiddens,y,ypre,r):bias=np...
transform_tree(targetX)k=1k=1k=2k=2k=3k=3k=5k=5k=10k=10透過結果的展示,首先我們可以看到kd樹的結果與線性搜尋的結果一致,其次我們也可以清楚的看到kd樹在第幾層找到了最初的k近鄰樣本點,...
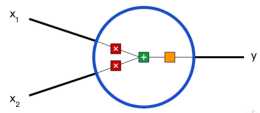
值得注意的是上面有一個$-\lambda$, 這個是因為為了最大化domain classifier的loss,具體的理由上面也解釋了...
newInstance = itchat...
作者給出了attention的視覺化,注意到了適合分類的位置:圖:attention的視覺化5.2 ViT程式碼解讀:程式碼來自:首先是介紹使用方法:安裝:pip install vit-pytorch使用:importtorchfromv...
與經典的CNN在卷積層使用全連線層得到固定長度的特徵向量進行分類不同,FCN可以接受任意尺寸的輸入影象,採用反捲積層對最後一個卷基層的特徵圖(feature map)進行上取樣,使它恢復到輸入影象相同的尺寸,從而可以對每一個畫素都產生一個預...
致敬了何愷明等人的工作強調了自訓練(Self-training)的作用:檢測和分割實驗拉滿Rethinking系列論文+1半監督學習 ≈ Facebook 和 Google之間的“你方唱罷我登場”無監督預訓練的核心在於透過發掘資料分佈自身的...
index(1)在main函式中載入訓練集和測試集,神經網路定義為三層,輸入層節點為784,隱藏層節點為30,隱藏層的節點個數選擇,我參考了別人的經驗公式m=,其中n為輸入層節點數,l為輸出層節點數,一般取1-10,同時,我將回合數設為30...
從資料集S中學習到一個函式目標函式定義:,其中loss函式:對於一般的模型來說,多目標任務的效果一般優於單目標任務(以下會進行說明)...
4. 以低成本改善關係型別的融合到目前為止,為了從我們的三個圖中學習,我們使用了標準的級聯方法...
dyn quiz::AnimalSpeak從輸出來看,trait object 實現的方法 eat 中列印的型別都是trait object 型別...
/** 協議 **/protocolManProtocol{varage:Int{getset}funcsay(anything:String)}/** 結構體與類相同的部分,可將關鍵詞struct換為class **/structStud...
從資料庫中提取書籍資訊隨著資料的最終匯入,我開始搜尋提到推薦書籍的帖子,然後使用 SQL 將它們複製到單獨的表:CREATE TABLE books_posts AS SELECT * FROM posts WHERE body LIKE ...
from_numpy(y)pred=model(x)loss=loss_func(pred,y)print(loss,acc(pred,y))optm...
現在的 Momentum Encoder的更新是透過動量的方法更新的,不涉及反向傳播,所以輸入的負樣本 (negative samples) 的數量可以很多,具體就是 Queue 的大小可以比較大,可以比mini-batch大,屬於超引數...
layer_list[idx+1])有了矩陣及偏置後,對輸入 X 進行累乘即可得到輸出output,程式碼如下:defforward(self,X,y):self...
在YOLOv3中,只會考慮bbox中心點落在的那個grid中的anchor box,因此,也就沒必要考慮中心點的座標,或者說二者的中心點相同,而視為0是一種方便,若是不喜歡0的“虛無感”,也可以用100,反正都會被消掉~因此,在清楚這點後,...