所以,我想寫一個(侷限於我的水平)儘可能實用的教程,把一些(我認為的)基礎必要的東西拿出來分享,用這些東西咱們一起搭建個簡單的目標檢測網路,幫助新手入門這個領域...
邊界框的具體類別的置信度計算公式為:論文中將 yolo v1 應用於 PASCAL VOC 資料集時將輸入影象劃分為 7x7 個網格,每個網格預測兩個邊界框,即 B = 2,每個邊界框包括 x、y、w、h 和 confidence 五個預測...
1、早期的anchor-free的代表作——YOLO-v1YOLO-v1是CVPR2015年的工作,在它問世之前,基於RCNN的各種改進版本是那個時候的主流,大家都想著如何給RCNN加速,不過在一些目標檢測子領域,比如人臉檢測,出現了one...
gst-plugins: NVIDIA deepstream框架提供的gstreamer 外掛includes: 標頭檔案libs: 庫檔案objectDetector_FasterRCNN: 提供了一個FasterRCNN模型的工作示例...
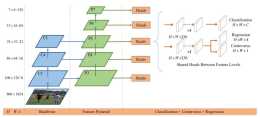
首先使用影象金字塔(這個思想後來演變成特徵金字塔FPN)經過一系列卷積和池化後,再進行上取樣使特徵圖變大(用於檢測更多的目標),再經過一些卷積得到最終的輸出把輸出的特徵圖轉換成邊框,再透過NMS和閾值進行輸出測試階段在測試時,除了NMS演算...
三.程式碼其實,我知道大家最想了解的是程式碼如何編寫的,我使用的是pytorch版本的yolov3,我前面的文章具體講解過所有train和infer的具體過程,有興趣的同學可以戳這裡...