也即其名字所示綜上所示,即 Back Propagation 的流程,傳說中 BP 的四個公式也在過程中都推導過了,如下Mini-batch Gradient Descent我們都知道 GD(Gradient Descent) 的本質就是希...
Factorization Machines(FM)模型如下所示,具有以下幾個優點:模型公式前兩項為一個線性模型,相當於LR模型的作用第三項為一個二次交叉項,能夠自動對特徵進行交叉組合透過增加隱向量,模型訓練和預測的計算複雜度降為了O(N)...
為了描述這兩個分佈的相似性,於是就引入了 Cross Entropy Loss,其定義如下:對於兩類分類,,可以簡化為:還有一點需要注意,在上一章介紹DNN時,我們假設了 Output Layer 中從到的變換是普通的 Activation...
作者表示,雖然關於股價預測的方法和論文都有很多,但都未展示這些方法在實際投資場景的表現,而作者團隊基於日本的股市,用真實的股票資料構造了投資組合,依次來展示預測方法的收益表現...
至於為什麼是在 Activation Function 前放置,而非整個 Hidden Layer 前放置,我們下面會解釋求解引數:利用 BP 求解 DNN 中的引數所以,DNN 與 BN+DNN 的結構分別如下(下圖中的文中 Hidden...
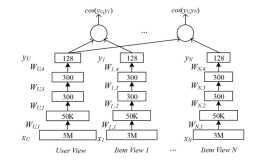
動機為什麼是MV-DNN:協同過濾推薦(CF),無法解決新使用者推薦基於內容推薦,基於線上user-profile的使用者興趣表示不準確本文提出基於DSSM架構的深度興趣模型匹配模型,可以很好的將user和item的大量特徵編碼到隱語義空間...
論文:Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy 邊緣智慧:裝置-邊緣協同進行按需深度學習模型聯合推理Bran...