特別照料(或行動、處理)5...
MLP也是L層block堆積而成(如下圖所示),輸入為X(n*d),n的長度,維度是d,每個block定義如下:U和V就是圖中Channel Proj,對embeddings做線性對映,類似transformer中的FFNs,啟用函式用的G...
003),loss=“categorical_crossentropy”,metrics=[“acc”])model...
產生的權重向量和query feature進行channel-wise multiplication,得到的結果進入spatial attention generator...
不管是Seq2seq或是Attention model,其中使用的都是RNN,RNN的缺點就是無法平行化處理,導致模型訓練的時間很長,有些論文嘗試用CNN去解決這樣的問題,像是Facebook提出的Convolutional Seq2seq...
二、問題定義按論文設定,預測,可看做t時刻的指數價格...
Metric embedding適用與處理稀疏的資料和未觀測到的資料,能夠避開dot-product違背矩陣函式的重要不等式性質導致次優解的缺點Model learning模型任務是基於time step t 和 使用者長期偏好給出t+1時...
decoder第二個子層是mutli-head self attention,其中encoder部分的輸出與decoder第一個子層的輸出作為輸入,本質還是做多抽頭的注意力,然後還要經過add&norm輸出...
感知器: 每一時刻智慧體只能觀測到環境(影象)的部分資訊,本論文假設智慧體使用一個頻寬有限的感知器提取出影象上位置附近的一個類似於視網膜的表徵資料...
最後就是結尾了結尾就是總結這件事有好的影響、不好的影響、或者兩者都有1、總之,xxx應該值得我們重視(加粗部分是下面英文的橫線部分),現在是我們充分利用現有大量機會的時候了,我們應該盡最大努力宣傳這一現象/解決這一問題...
pdf更多 ICCV 2021 的論文和程式碼,以及相關的報告和解讀都進行整理(歡迎star)GitHub - DWCTOD/ICCV2021-Papers-with-Code-Demo: ICCV 2021 paper with code...
《CPTR: FULL TRANSFORMER NETWORK FOR IMAGE CAPTIONING》CPTR: Full Transformer Network for Image成為職業coser需要幹什麼Captioning3...
如何看待計算機視覺未來的走向使用Dice loss實現清晰的邊界檢測CNN結構演變總結(一)經典模型CNN結構演變總結(二)輕量化模型CNN結構演變總結(三)設計原則CNN視覺化技術總結(一)——特徵圖視覺化CNN視覺化技術總結(二)——卷...
Attention OCR源於2019年12月由北京航空航天大學和中科院自動化研究所的研究者發表在arxiv上的“A Feasible Framework for Arbitrary-Shaped Scene Text Recognitio...
二、文字處理中單詞向量編碼的方式在文字處理中,我們對單詞進行向量編碼通常有兩種方式:獨熱編碼(one-hot encoding):用N位的暫存器對N個狀態編碼,通俗來講就是開一個很長很長的向量,向量的長度和世界上存在的詞語的數量是一樣多的,...
此外,”The transformer”用了8個attention head,所以我們會產生8組encoder/decoder,每一組都代表將輸入文字的隱向量投射到不同空間,如果我們重複計算剛剛所講的self-attention,我們就會得...
static_model_path, input_spec=[input_ids, attention_mask])def test_static(args):“”“對靜態圖模型進行測試”“”# 設定顯示卡資訊os...
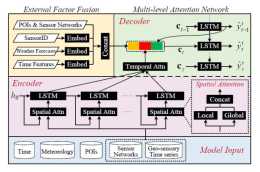
這篇paper提出了一種GeoMAN(Multi-level Attention Network)結構的預測模型,該模型基於Encoder-Decoder結構,在時空資料預測問題上首次引入了多層注意力機制,對各感測器之間的動態時空關聯性進行...
Attention-Guided Adversarial Loss就是加了 attention mask 的4通道輸入對抗損失:Cycle-Consistency Loss就是CycleGAN中的迴圈一致性損失:Pixel Loss就是生成...